

Momentum Contrast for Unsupervised Visual Representation Learning
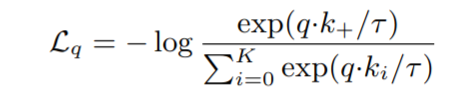
伪代码:
1 | # f_q, f_k: encoder networks for query and key |
亮点
Dictionary as a queue
在使用key encoder(momentum encoder)创建负样本,并把encode过的负样本存在一个queue(FIFO)中方便后续对比时直接使用,每次训练都会使用一个新的mini batch,此时会将此mini batch中的样本encode之后加入queue并删除存在最久的那个mini batch的样本(因为考虑到最老的mini batch使用的encoder是最过时的,所以FIFO是非常合理的),这样可以有效控制负样本的数量,也就是公式中的K。
- 节省字典的计算开销
- 而且mini batch大小可以直接和负样本脱钩
Momentum update
因为负样本数量(字典/队列)很大,所以没办法给key encoder回传梯度,所以可以考虑把query encoder的参数直接复制给key encoder,但过快改变的key encoder会导致样本字典的特征不一致,所以使用动量更新的方式。
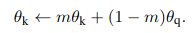
过往工作对比
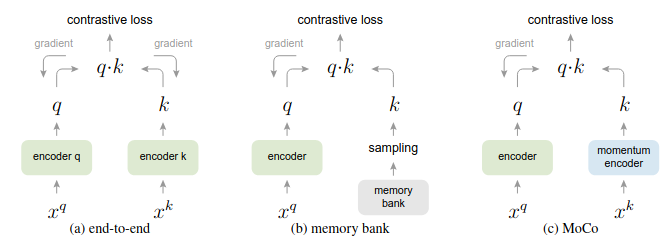
b)
只有一个编码器进行学习。Memory bank存下了所有样本的key。每当梯度回传后,会把memory bank被本次训练中被采样过的key使用新的encoder进行更新。
- 缺乏特帧一致性
- 需要训练一阵个epoch才能更新一遍memory bank
MoCo和memory bank 更接近,但是使用了queue dictionary和momentum update
Momentum Contrast for Unsupervised Visual Representation Learning

